Find Me In The Crowd
AI-Powered Intelligent Video Retrieval for Large-Scale Events
An advanced video retrieval platform designed to solve a computer vision challenge: automating the discovery of specific individuals within terabytes of unstructured event footage. The system enables users to upload a reference photograph and retrieve all video segments in which they appear, transforming unsearchable video archives into accessible digital content.
Jump to
Executive Summary
Large-scale events such as concerts, conferences, and festivals generate substantial amounts of multi-angle video data. While this footage contains valuable content, it often remains unsearchable and underutilized due to the impracticality of manually locating specific attendees within extensive video archives.
Find Me In The Crowd addresses this challenge by providing a scalable solution where users upload a single reference photograph to locate and retrieve every video segment in which they appear. The system delivers results with timestamps, camera identifiers, and playback capabilities, eliminating the need for manual video scrubbing.
Developed as a capstone project, this system is production-ready and handles real-world scale. It processes terabytes of video, indexes millions of facial embeddings, and delivers sub-second search results while maintaining accuracy under challenging conditions including variable lighting, high crowd density, and diverse camera angles.
Objective
Transform passive, unsearchable video archives into dynamic, searchable digital assets. Enable users to retrieve specific moments from large-scale event footage through automated facial recognition and intelligent video segmentation.
Problem Statement
Traditional video retrieval methods are insufficient for visual content where the primary query is a person's identity. Keyword-based search and manual video scrubbing do not scale to large archives. This represents a "data-rich, information-poor"paradox: substantial valuable content exists, but effective retrieval mechanisms are lacking.
Technical Challenges
High Dimensionality and Scale
A single event can generate tens of thousands of frames across multiple cameras. Processing this requires handling high-dimensional visual data at a scale that exceeds the capabilities of traditional database systems.
Unconstrained Environments
Unlike controlled environments, event footage presents challenges including variable lighting conditions, occlusions, high crowd density, and diverse camera angles. These factors complicate computer vision tasks.
Latency Requirements
The system must transition from computationally intensive indexing phases to sub-second search responses. This requirement distinguishes production systems from research prototypes.
Output Format Requirements
Users require watchable video clips with temporal context, not merely lists of timestamps or raw frame detections. The system must aggregate discrete detections into coherent video segments.
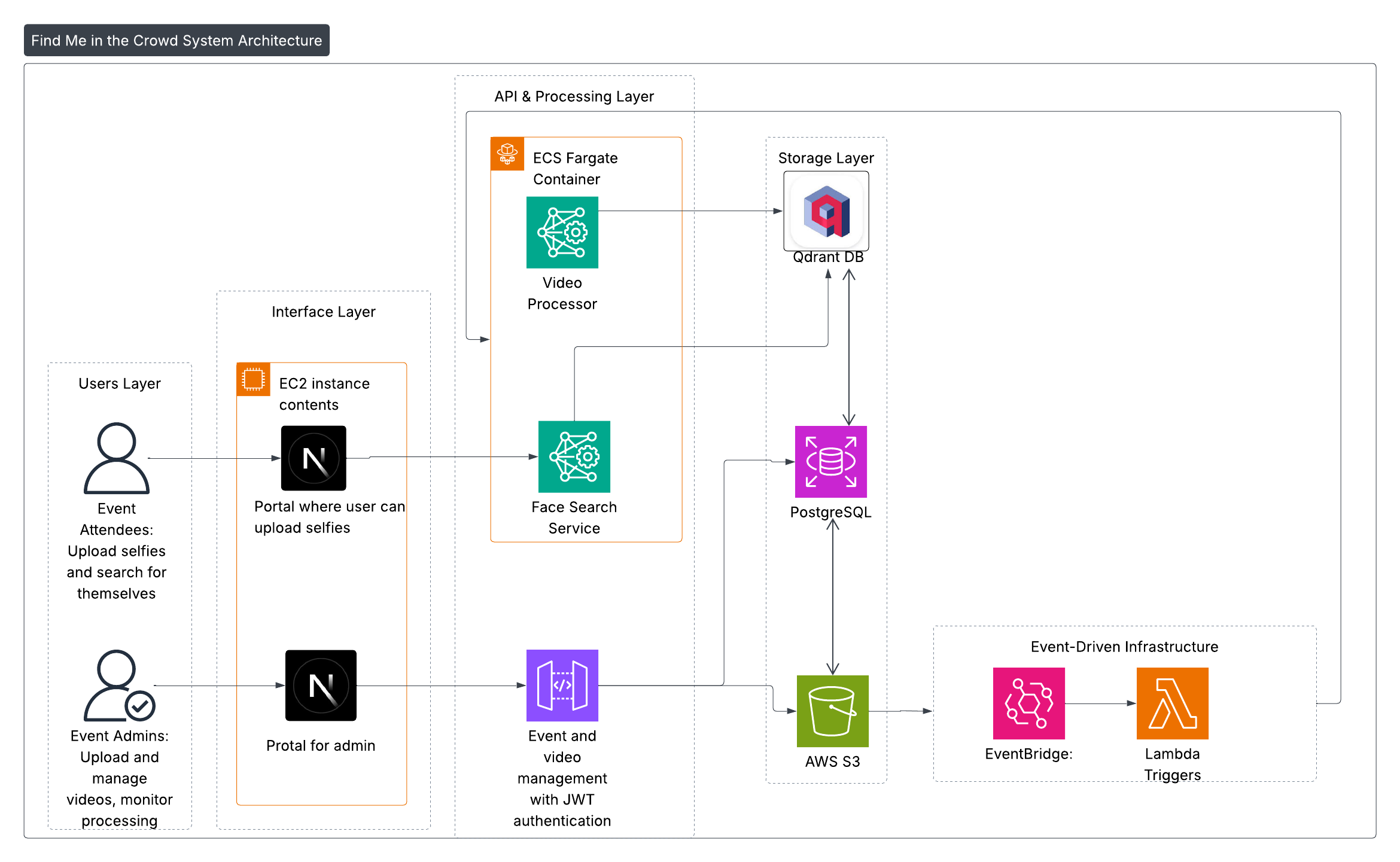
System Architecture
To balance computational load with low-latency search requirements, the system employs a Dual-Pipeline Architecturethat decouples resource-intensive analysis from user-facing interactions. This design separates offline indexing operations from online retrieval operations.
Offline Indexing Pipeline
This pipeline handles video ingestion and analysis before user queries occur, ensuring the system is prepared for search operations. All processing occurs asynchronously.
Video Ingestion
Videos are uploaded directly to cloud storage, bypassing application server bottlenecks. This approach ensures reliability for large file transfers.
Automated Processing
Upload events trigger serverless compute instances to begin processing immediately. The architecture is event-driven, requiring no manual intervention.
Frame Analysis
The system employs intelligent frame sampling to balance temporal resolution with processing efficiency. State-of-the-art face detection networks localize and align faces within video streams.
Vector Embedding Generation
Detected faces are converted into high-dimensional vector embeddings. These vectors abstract facial features into numerical representations that are robust to moderate changes in expression and pose.
Indexing
Generated embeddings, coupled with metadata including timestamps and camera identifiers, are stored in a vector database optimized for nearest-neighbor search operations.
Online Retrieval Pipeline
This pipeline is optimized for low-latency responses, handling user search requests synchronously with minimal delay.
Query Formulation
When a user uploads a reference image, the system validates the input and generates a query vector using the same encoding engine employed during indexing. This ensures consistency between query and indexed vectors.
Similarity Search
The system executes cosine similarity search against the vector index. To optimize performance, the search space is constrained using metadata filters such as event identifiers and time ranges.
Result Aggregation
Raw search results are processed through a custom aggregation engine that groups detections and adds temporal context buffers, transforming discrete frame hits into watchable video segments.
Core Technologies and Methodology
The system integrates computer vision, vector mathematics, and cloud engineering to achieve its objectives.
Deep Facial Representation
Rather than relying on pixel-level matching, the system abstracts facial identity into a mathematical vector space. This approach enables recognition across variations in expression, pose, and lighting conditions.
Embedding Model
The system utilizes ArcFace (Additive Angular Margin Loss) architectures. This model was selected for its ability to maximize the decision margin between different identities, ensuring high accuracy in unconstrained scenarios.
Vector Normalization
Embeddings are L2-normalized, enabling the use of angular distance(cosine similarity) as a reliable metric for identity verification. This approach provides computational efficiency and accuracy.
Vector Search Architecture
Traditional relational databases cannot efficiently query similarity relationships. The system employs Qdrant, a vector database that manages millions of embeddings and executes Approximate Nearest Neighbor (ANN) searches in milliseconds.
Hybrid filtering combines vector search performance with metadata precision. The system supports filtering by event identifiers, time ranges, and camera locations, enabling efficient query refinement while maintaining search speed.
Temporal Clustering Algorithm
Raw vector search returns individual frame detections, which presents a fragmented user experience. A proprietary Temporal Grouping Algorithm addresses this by intelligently clustering detections based on temporal proximity and handling occlusions.
Temporal Clustering
Groups frame detections based on temporal proximity. If an individual appears in frames 100, 101, 102, and 105, the algorithm identifies a continuous presence from frame 100 to 105.
Occlusion Handling
Accounts for momentary occlusions such as head turns or objects passing between the camera and subject. Small temporal gaps are automatically bridged to maintain continuity.
Context Buffering
Expands clip boundaries beyond exact detection frames to provide temporal context. This ensures users receive complete moments rather than abrupt cuts.
Technology Stack
The system employs a modern, type-safe, and containerized technology stack designed for maintainability and scalability.
Backend and AI
- ▸Python 3.10+ — Selected for its comprehensive AI and machine learning ecosystem
- ▸FastAPI — Chosen for asynchronous support (ASGI), essential for handling concurrent I/O-bound search requests
- ▸InsightFace and OpenCV — Provide the face detection and processing pipeline
- ▸ONNX Runtime (GPU) — Optimizes model inference speeds, reducing computational cost for embedding generation
Infrastructure and Data
- ▸Qdrant — Vector database that scales to millions of embeddings
- ▸PostgreSQL (AWS RDS) — Manages structured business logic, event details, and processing states
- ▸Amazon S3 — Handles raw video assets and utilizes signed URLs for secure, time-limited playback access
Frontend Interface
- ▸Next.js (React 18) with TypeScript — Provides modern, type-safe frontend development
- ▸Tailwind CSS and Radix UI — Enable responsive, accessible component architecture
- ▸User Experience Features — Includes drag-and-drop uploads, skeleton loading states for perceived performance, and an interactive video player that seeks precisely to detected timestamps
Cloud-Native Deployment
Scalability was a primary requirement. The system is deployed entirely on Amazon Web Services (AWS) using a serverless container strategy that enables automatic scaling.
Containerization
All services are containerized using Docker with multi-stage builds to optimize image size and security. This approach reduces deployment complexity and improves portability.
Orchestration: AWS Fargate
Dynamic Scaling
The Indexing Service runs as on-demand Fargate Tasks. This architecture enables parallel processing of multiple video uploads without maintaining idle server infrastructure, optimizing cost efficiency.
High Availability
The Search Service runs as a persistent Fargate Service behind an Application Load Balancer. The service auto-scales based on CPU utilization to handle traffic variations automatically.
Continuous Integration and Deployment
Automated pipelines via GitHub Actions manage testing, building, and deployment to Amazon ECR/ECS. This enables rapid iteration cycles and ensures consistent deployment processes.
Performance and Reliability
The system underwent rigorous testing to ensure it meets the demands of real-world usage scenarios.
Low Latency
The runtime search pipeline is optimized to deliver results with sub-second latency, maintaining performance even under concurrent load conditions.
Processing Efficiency
Through intelligent frame sampling and resource optimization, video processing throughput improved by approximately 90% compared to baseline approaches.
Accuracy Metrics
Through ablation studies on similarity thresholds, the system was tuned to balance Precision and Recall, minimizing false positives while ensuring comprehensive detection coverage.
Key Engineering Decisions
Trade-off: Accuracy vs. Performance
Accepted 15-20% accuracy loss to achieve ~90% speed improvement.
Reasoning: For this use case, recall mattered more than precision because users could visually confirm results, allowing aggressive speed optimizations. The slight reduction in accuracy was acceptable given the substantial performance gains and the ability for users to validate results manually.
Engineering Solutions
Data Consistency
Variable frame rates in source videos initially caused timestamp drift, affecting accurate clip boundary determination. This was resolved through implementation of monotonic time sorting and synchronization logicto ensure precise segment boundaries.
User Experience Enhancement
Raw AI outputs can be fragmented and difficult to interpret. By implementing "Contextual User Windows"(temporal buffering), discrete detection points were transformed into coherent, watchable video segments suitable for user consumption.
System Architecture Diagram
Privacy and Ethical Safeguards
The system implements comprehensive privacy protections and ethical safeguards in compliance with PDPA and GDPR regulations. The following technical measures ensure user data protection:
Explicit Consent Management
The system implements explicit user and administrator consent flows. Users must provide informed consent before their images are processed, and administrators must acknowledge data handling policies before accessing the system.
Data Isolation
No cross-event identity linking: The system is designed to prevent identity correlation across different events. Each event maintains isolated data stores, ensuring that facial recognition data from one event cannot be linked to identities in another event.
Minimal Data Storage
Embeddings stored without raw images: After processing, only vector embeddings are retained in the database. Original images are not stored, reducing privacy risks and storage requirements. Raw video files remain in secure, access-controlled storage with time-limited access.
Data Deletion Capabilities
The system provides manual data deletion features that allow users and administrators to request removal of their data. This includes deletion of embeddings, metadata, and associated video segments, with confirmation workflows to ensure proper data removal.
Conclusion
Find Me In The Crowd demonstrates the capacity to architect and deliver a full-stack AI solution that addresses a complex data retrieval problem. By successfully integrating deep learning, vector search, and serverless cloud architecture, this project highlights proficiency in building systems that are technically rigorous, scalable, and user-centric.
The platform effectively transforms hours of passive, unstructured video footage into dynamic, searchable digital assets. This showcases the potential of intelligent video analytics in the event industry and demonstrates practical applications of computer vision and vector database technologies.
The system's architecture, performance characteristics, and user experience design represent a comprehensive approach to solving real-world problems through systematic engineering and careful technology selection.
© 2026 Find Me In The Crowd. All rights reserved.
This project case study is the intellectual property of the developer. Unauthorized reproduction or distribution is prohibited.